A Perceptron in just a few Lines of Python Code
A Perceptron in just a few Lines of Python Code
Content created by webstudio Richter alias Mavicc on March 30. 2017.
The perceptron can be used for supervised learning. It can solve binary linear classification problems. A comprehensive description of the functionality of a perceptron is out of scope here. To follow this tutorial you already should know what a perceptron is and understand the basics of its functionality. Additionally a fundamental understanding of stochastic gradient descent is needed. To get in touch with the theoretical background, I advise the Wikipedia article:
Furthermore I highly advise you the book of Schölkopf & Smola. Do not let the math scare you, as they explain the basics of machine learning in a really comprehensive way:
Schölkopf & Smola (2002). Learning with Kernels. Support Vector Machines, Regularization, Optimization, and Beyond.
To better understand the internal processes of a perceptron in practice, we will step by step develop a perceptron from scratch now.
Give Me the Code!
import numpy as np
X = np.array([
[-2,4,-1],
[4,1,-1],
[1, 6, -1],
[2, 4, -1],
[6, 2, -1],
])
y = np.array([-1,-1,1,1,1])
def perceptron_sgd(X, Y):
w = np.zeros(len(X[0]))
eta = 1
epochs = 20
for t in range(epochs):
for i, x in enumerate(X):
if (np.dot(X[i], w)*Y[i]) <= 0:
w = w + eta*X[i]*Y[i]
return w
w = perceptron_sgd(X,y)
print(w)
[ 2. 3. 13.]
Our Ingredients
First we will import numpy to easily manage linear algebra and calculus operations in python. To plot the learning progress later on, we will use matplotlib.
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
Stochastic Gradient Descent
We will implement the perceptron algorithm in python 3 and numpy. The perceptron will learn using the stochastic gradient descent algorithm (SGD). Gradient Descent minimizes a function by following the gradients of the cost function. For further details see:
Wikipedia - stochastic gradient descent
Calculating the Error
To calculate the error of a prediction we first need to define the objective function of the perceptron.
Hinge Loss Function
To do this, we need to define the loss function, to calculate the prediction error. We will use hinge loss for our perceptron:
$c$ is the loss function, $x$ the sample, $y$ is the true label, $f(x)$ the predicted label.
This means the following:
So consider, if y and f(x) are signed values $(+1,-1)$:
- the loss is 0, if $y*f(x)$ are positive, respective both values have the same sign.
- loss is $1-y*f(x)$ if $y*f(x)$ is negative
Objective Function
As we defined the loss function, we can now define the objective function for the perceptron:
We can write this without the dot product with a sum sign:
So the sample $x_i$ is misclassified, if $y_i \langle x_i,w \rangle \leq 0$. The general goal is, to find the global minima of this function, respectively find a parameter $w$, where the error is zero.
Derive the Objective Function
To do this we need the gradients of the objective function. The gradient of a function $f$ is the vector of its partial derivatives. The gradient can be calculated by the partially derivative of the objective function.
This means, if we have a misclassified sample $x_i$, respectively $ y_i \langle x_i,w \rangle \leq 0 $, update the weight vector $w$ by moving it in the direction of the misclassified sample.
With this update rule in mind, we can start writing our perceptron algorithm in python.
Our Data Set
First we need to define a labeled data set.
X = np.array([
[-2, 4],
[4, 1],
[1, 6],
[2, 4],
[6, 2]
])
Next we fold a bias term -1 into the data set. This is needed for the SGD to work. Details see The Perceptron algorithm
X = np.array([
[-2,4,-1],
[4,1,-1],
[1, 6, -1],
[2, 4, -1],
[6, 2, -1],
])
y = np.array([-1,-1,1,1,1])
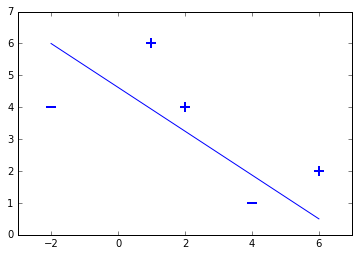
This small toy data set contains two samples labeled with $-1$ and three samples labeled with $+1$. This means we have a binary classification problem, as the data set contains two sample classes. Lets plot the dataset to see, that is is linearly seperable:
for d, sample in enumerate(X):
# Plot the negative samples
if d < 2:
plt.scatter(sample[0], sample[1], s=120, marker='_', linewidths=2)
# Plot the positive samples
else:
plt.scatter(sample[0], sample[1], s=120, marker='+', linewidths=2)
# Print a possible hyperplane, that is seperating the two classes.
plt.plot([-2,6],[6,0.5])
[<matplotlib.lines.Line2D at 0x7f2d223415f8>]
Lets Start implementing Stochastic Gradient Descent
Finally we can code our SGD algorithm using our update rule. To keep it simple, we will linearly loop over the sample set. For larger data sets it makes sence, to randomly pick a sample during each iteration in the for-loop.
def perceptron_sgd(X, Y):
w = np.zeros(len(X[0]))
eta = 1
epochs = 10
for epoch in range(epochs):
for i, x in enumerate(X):
if (np.dot(X[i], w)*Y[i]) <= 0:
w = w + eta*X[i]*Y[i]
return w
Code Description Line by Line
line 2: Initialize the weight vector for the perceptron with zeros
line 3: Set the learning rate to 1
line 4: Set the number of epochs
line 6: Iterate n times over the whole data set.
line 7: Iterate over each sample in the data set
line 8: Misclassification condition $y_i \langle x_i,w \rangle \leq 0$
line 9: Update rule for the weights $w = w + y_i * x_i$ including the learning rate
Let the Perceptron learn!
Next we can execute our code and check, how many iterations are needed, until all sampels are classified right. To see the learning progress of the perceptron, we add a plotting feature to our algorithm, counting the total error in each epoch.
def perceptron_sgd_plot(X, Y):
'''
train perceptron and plot the total loss in each epoch.
:param X: data samples
:param Y: data labels
:return: weight vector as a numpy array
'''
w = np.zeros(len(X[0]))
eta = 1
n = 30
errors = []
for t in range(n):
total_error = 0
for i, x in enumerate(X):
if (np.dot(X[i], w)*Y[i]) <= 0:
total_error += (np.dot(X[i], w)*Y[i])
w = w + eta*X[i]*Y[i]
errors.append(total_error*-1)
plt.plot(errors)
plt.xlabel('Epoch')
plt.ylabel('Total Loss')
return w
print(perceptron_sgd_plot(X,y))
[ 2. 3. 13.]
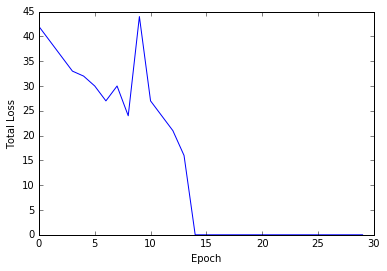
This means, that the perceptron needed 14 epochs to classify all samples right (total error is zero). In other words, the algorithm needed to see the data set 14 times, to learn its structure.
The weight vector including the bias term is $(2,3,13)$.
We can extract the following prediction function now:
The weight vector is $(2,3)$ and the bias term is the third entry -13.
Evaluation
Lets classify the samples in our data set by hand now, to check if the perceptron learned properly:
First sample $(-2, 4)$, supposed to be negative:
Second sample $(4, 1)$, supposed to be negative:
Third sample $(1, 6)$, supposed to be positive:
Fourth sample $(2, 4)$, supposed to be positive:
Fifth sample $(6, 2)$, supposed to be positive:
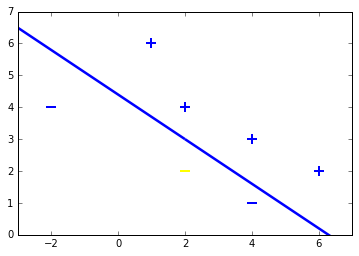
Lets define two test samples now, to check how well our perceptron generalizes to unseen data:
First test sample $(2, 2)$, supposed to be negative:
Second test sample $(4, 3)$, supposed to be positive:
Both samples are classified right. To check this geometrically, lets plot the samples including test samples and the hyperplane.
for d, sample in enumerate(X):
# Plot the negative samples
if d < 2:
plt.scatter(sample[0], sample[1], s=120, marker='_', linewidths=2)
# Plot the positive samples
else:
plt.scatter(sample[0], sample[1], s=120, marker='+', linewidths=2)
# Add our test samples
plt.scatter(2,2, s=120, marker='_', linewidths=2, color='yellow')
plt.scatter(4,3, s=120, marker='+', linewidths=2, color='blue')
# Print the hyperplane calculated by perceptron_sgd()
x2=[w[0],w[1],-w[1],w[0]]
x3=[w[0],w[1],w[1],-w[0]]
x2x3 =np.array([x2,x3])
X,Y,U,V = zip(*x2x3)
ax = plt.gca()
ax.quiver(X,Y,U,V,scale=1, color='blue')
<matplotlib.quiver.Quiver at 0x7f2d22240400>
Final Thoughts
Thats all about it. If you got so far, keep in mind, that the basic structure is the SGD applied to the objective function of the perceptron. This is just four lines of code. It contains all the learning magic. Cool isnt it?
I am looking forward for your comments.
Greetings from webstudio, Mavicc